Eigen MAGMA backend implementation project
Page 1 of 1 (12 posts)
Tags:
None
|
Registered Member 
|
Hello,
I have "created a fork" of Eigen 3.2 and incorporated some (small) progress I have preparing a MAGMA backend to best exploit GPU & CPU. This is an alternative to using MKL which indirectly uses MKL because MAGMA does use MKL in the back. I have been testing it using MAGMA 1.4.0-beta2 and so far all my project tests pass without having to change our Eigen-based code base which is great! Anyone who wants to contribute please contact me to bravegag@hotmail.com or via the GitHub account below. The code base is available here: https://github.com/bravegag/eigen-magma I have working the first port corresponding to GeneralMatrixMatrix_MAGMA.h which in reality uses MAGMA API but invokes CUBLAS which is slightly faster: https://github.com/bravegag/eigen-magma ... ix_MAGMA.h Another partial implementation (currently a bit of work in progress) ColPivHouseholderQR_MAGMA.h it is missing enabling the macro for float and complex types: https://github.com/bravegag/eigen-magma ... QR_MAGMA.h I have been adding implementations prioritizing the functions we use as part of our project. The remaining *_MAGMA.h implementations are simply mock copies of the MKL counterparts with some basic pre-processing changes i.e. MKL -> MAGMA replacement. Best regards, Giovanni |
|
Registered Member
|
I have created a simple benchmark project to check the implementation:
https://github.com/bravegag/eigen-magma-benchmark I have added documentation including the Gflops results for DGEMM and DGEQP3 so far implemented. |

Moderator
|
Great work. I've updated the respective bugzilla entry: http://eigen.tuxfamily.org/bz/show_bug.cgi?id=461.
|
|
Registered Member
|
Hi ggael,
Thank you. I am currently in holidays but next week will continue expanding the project to other products and factorizations. If you give me your GitHub account I can give you commit access to the project. Best regards, Giovanni |
|
Registered Member
|
Quick update, I have additionally implemented:
- dgemv (matrix vector multiplication) - dtrsm (triangular matrix solver) - dpotrf (Cholesky decomposition) The results are very disappointing, unless I have bugs (e.g. copying Host <-> Device more memory than needed ) MAGMA overall and taking into account the memory transfer underperforms in these three cases see: https://github.com/bravegag/eigen-magma-benchmark The Cholesky decomposition result is the most surprising because Eigen beats both MKL and MAGMA (see the Gflops): https://raw.github.com/bravegag/eigen-m ... gflops.png If anyone would be willing to donate a code review I will be more than happy  Best regards, Giovanni |
|
Registered Member
|
Quick update:
I have done some bugfixes and included ?gesvd as well. The benchmark results have been updated to also reflect when it is using MAGMA and when it is using CUBLAS. The benchmark results are now embedded: https://github.com/bravegag/eigen-magma-benchmark So far the MAGMA backend pays off for dgemm (Matrix Matrix product), dgeqp3 (QR decomposition Household with column pivoting), and dgesvd (SVD decomposition). Of course using a different setup, results may differ i.e. using a Tesla K20 card will improve the MAGMA results in all benchmarks but currently I use the cheaper nVidia GTX Titan solution (where I can get 3x cards for the price of one Tesla K20). Best regards, Giovanni |
|
Moderator
|
Hi, here is fix for gpotrf (the input matrix was not SPD):
|
|
Registered Member
|
Thank you! I have applied the patch, benchmarking now, when the matrix is SPD then they are all slower ... I will upload the results as soon as they are ready. btw if you have suggestions how to improve the performance let me know. A few thoughts on how to improve:
1) when magma is enabled, then use pinned Host memory. 2) switch some methods to mgpu i.e. multi-gpu e.g. dpotrf has a mgpu version, maybe this could be configured via another define. 3) caching data copied to device but it is kind of hard to do at this level. Best regards, Giovanni UPDATE: results uploaded and MAGMA now shines! https://github.com/bravegag/eigen-magma-benchmark |
|
Registered Member
|
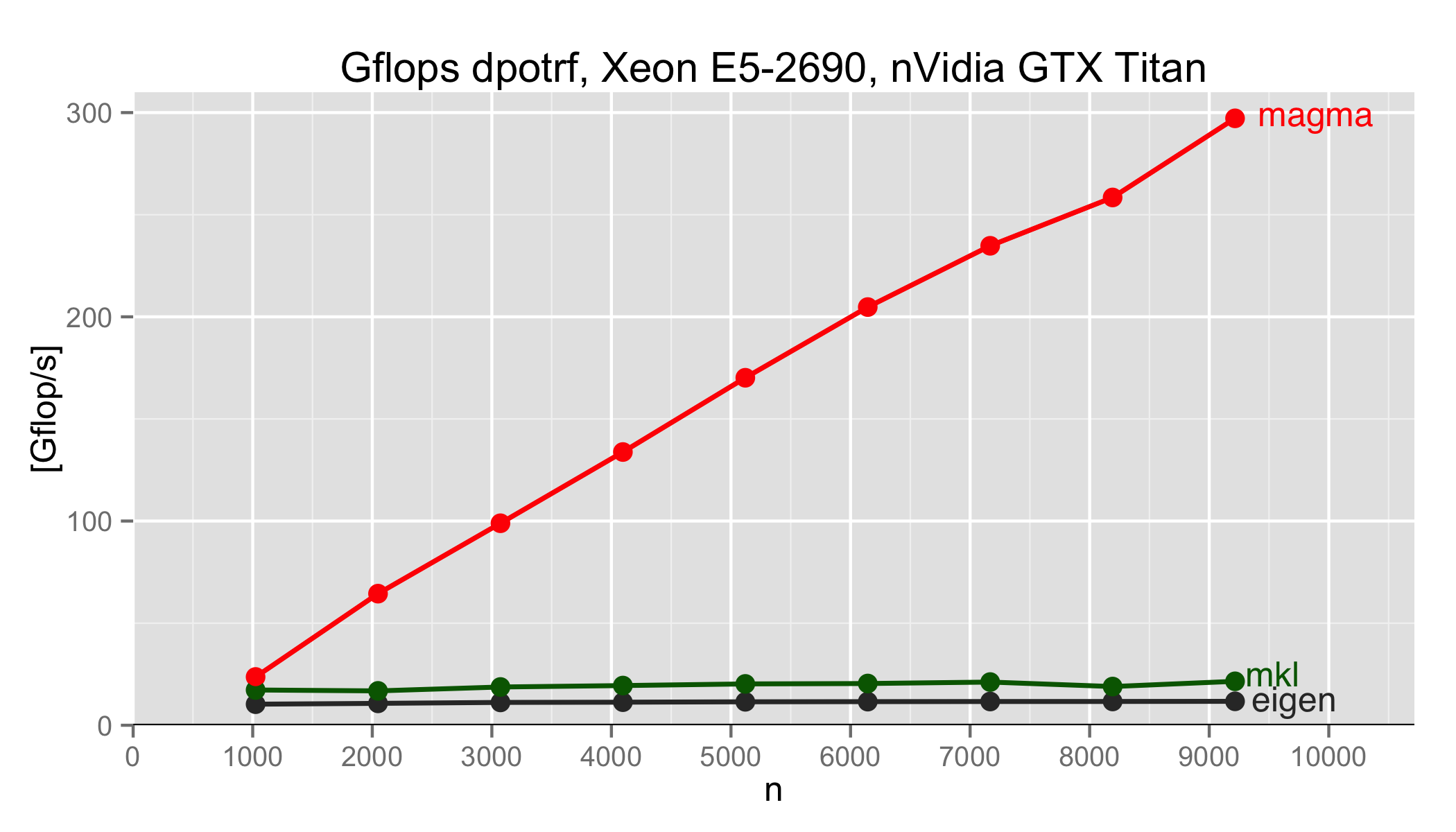
Major performance improvements in many of the factorizations e.g.
* DGEMM now tops at ~800 GFlop/s before was ~200 GFlop/s * DPOTRF now tops at ~250 GFlop/s before was ~125 GFlop/s The improvements are due to two aspects: * Enabling CUDA-Double precision on the nVidia driver. The Titan GTX has this peculiarity: the Double-precision performance ratio defaults to 1/24th of the Single-Precision performance and this ratio can be changed using the nvidia driver to 1/3 of the SP performance. * Upgrading to MAGMA official 1.4.0 release. PS: still benchmarking |
|
Registered Member
|
Benchmarks updated after doing this (nvidia.NVreg_EnablePCIeGen3=1 enabling PCIe v3.0 and the maximum link speed to 8GT/s instead of 5GT/s i.e. speed ups memory transfers Host <-> Device):
https://devtalk.nvidia.com/default/topi ... -on-titan/ This gave a performance edge on the Titan cards worth updating the benchmarks. |
|
Registered Member
|
Any progress on that?
By the way, why isn't Eigne on GitHub? |
|
Registered Member
|
Join to the question: is any progress here?
Now I am working on a project which needs MAGMA (or any GPU BLAS and LAPACK implementation). MKL does not satisfy to necessary performance (+ I need to build project for ARM with nvidia GPU, where I cannot use MKL). Eigen documentation tells me (https://eigen.tuxfamily.org/dox/TopicUs ... apack.html):
It works for me when I compile project with OpenBLAS or MKL, but when I try to link project with MAGMA libraries (libmagma.a for example) and flags EIGEN_USE_BLAS and EIGEN_USE_LAPACKE, I have many linking errors of undefined symbols in LAPACK and BLAS calls. In Eigen 3 sources I see some like this:
and in library symbols I see these instructions: like "magma_sgetrf_". Does it mean that I have invalid ##LAPACKE_PREFIX## ? Can you give me any tips for linking with MAGMA? Is this option supported? |

Page 1 of 1 (12 posts)
Bookmarks
Who is online
Registered users: Bing [Bot], Google [Bot], Sogou [Bot]





{kind=link}